As you probably already know, the general method of using search engines is quite simple: go to the search engine website, enter the search word (phrase), press “Enter” (or the “Find” button) - get the result - a list of links to the Internet pages containing the word or phrase you specified.
The difficulty lies in the details that are actually important: how to avoid “heaps of garbage” in search results; how to make sure that the search engine finds exactly the mention you need of the word (phrase) you are looking for, and not all the mentions in a row across all Internet sites; why in the list of resources found the most necessary and interesting sites are not in first place. And also why the search engine didn’t find anything useful at all, although you know for sure that this information is on the Internet, and several dozen more “why?” And How?".
Before clicking on the control panel to view the most advanced search tool customization options. In this window you will have the opportunity to activate “Image Search”, make changes to “ Appearance» search box to see the next model.
In the Opportunity Search option, you can enable promotions for your site that appear above the search results. An option that can significantly help your site's conversions. You can also enable autocomplete, allowing the user to get results faster by displaying useful queries when they start typing in the search box. This feature may take a few hours to start.
It was previously said that the best and most used Russian search sites are Google, Yandex, [email protected], Rambler. The best foreign search engines are www.Google.com and www.yahoo.com. It should be borne in mind that all these search engines have their own individual characteristics.
To begin with, their “coverage areas” may differ - Internet spaces that are indexed by search engines, that is, studied by them, and precisely on which the search is carried out.
This is the part that may make it difficult for some users who don't feel safe to edit their sites' files. My advice is to make a copy of the original file file before replacing it. The result will look something like below.
The most commonly used plugins for this task are easy to install. This will help anyone who is afraid or concerned about using the above method. With the plugin, it replaces the default search with a partial match search engine and sorts the results by relevance. Provides more control, allowing the administrator to have more information and a variety of features and customizable options.
- Search engines usually consist of three components:
- programs - a robot (spider) that navigates the network and collects information about its resources;
- a database containing information about network resources collected by a search robot;
- a search engine that allows the user to interact with the database.
Search robots-spiders, during their wanderings across the network, retrieve and index (evaluate) various types of information. Moreover, various robot programs have their own search characteristics and priorities. Some of them index every word in the document, others - only the most frequently occurring words. In general, document indexing is carried out according to many parameters: by the number of words in the document, by the size of the document, by its title, headings, links, etc.
You can find some of these features in free version plugin. Trading to another search engine is definitely an option that will improve your visitors' experience, and that's why you need to monitor the search results that most attract your visitors. If you are already using one of these solutions or know of another option, please share your experience with us.
In this article, we will explain to the reader what a search engine is, what is good and give a list of examples of search engines at the end. A search engine is a program that is used to search for some information. When entering words and indexing keywords, document, database or Internet result will be displayed.
Typically, search robots work “on a tip,” that is, the creator of a web page writes a request to a search engine with a request to index his document. A search robot is sent to the URL specified by him and does its job.
But search robots and spiders can independently navigate the web, following links in the documents they visit.
Soon after the advent of the Internet, the term search engine or search engine became associated with a site that is used to find information contained on other sites. This search consists of analyzing keywords from websites and presenting the results to the surfer. To do this, sites must be indexable for search engines, meaning they must regularly submit a list of keywords to search engines. Search engines also have the ability to investigate sites even if they do not submit a list of keywords.
Robots place the collected information in a database with which the user interacts by searching. Each search engine develops its own database, and most of the information in it may be the same as that of other search engines, but there are also significant differences.
It is also important by what criteria the search engine sorts the results found (placing some web pages at the beginning of the list, and others at the end).
What is the difference between "Search Engine" and "Search Engine"?
The first search engines used indexing of pages and built on it by categorizing them. Over two decades, they have evolved and today they use different technologies to produce results. Both are the same: Portugal uses the term "search engine" or "research tool", while Brazil uses "search engine".
There are other types of search engines. Generally, being included in a vertical search engine involves paying a monthly fee or cost per click. They are local or regional search engines and aim to provide information about companies and service providers.
Updated: July 28, 2017
Hello, dear readers of the blog site. , then its few users had enough of their own bookmarks. However, as you remember, it happened in geometric progression, and very soon it became more difficult to navigate in all its diversity.
Then directories appeared (Yahoo, Dmoz and others), in which their authors added and sorted various sites into categories. This immediately made life easier for the then, not yet very numerous users of the global network. Many of these catalogs are still alive today.
Local search guides or local search engine. . These are indexes of sites organized into categories and subcategories to allow the user to find sites using categories. Some are still in use, others are no longer, but the most famous are.
List of Portuguese and Brazilian search engines
Portugal and Brazil also have search engines. Here are some examples. 
This entry was posted in:, Listed by tags. Initially, companies were faced with the simple need to have a website, but at the same time, the online universe was filled with sites of all types, shapes, and basically saying the same thing as yours.
But after some time, the size of their databases became so large that the developers first thought about creating a search within them, and then about creating automated system indexing all Internet content to make it accessible to everyone.
The main search engines of the Russian-speaking segment of the Internet
As you understand, this idea was implemented with stunning success, but, however, everything turned out well only for a handful of selected companies that managed not to disappear on the Internet. Almost all search engines that appeared in the first wave have now either disappeared, languished, or were bought by more successful competitors.
The question asked in the introduction is actually much more comprehensive because in addition to the obvious need to appear before your competitor, we have the relationship between the keyword a user uses to find your service and the position your site appears in search results. Of course, if your site performs below the first 15 results, you're unlikely to get that potential customer's click.
Among the number of criteria that engines take into account, we can cite several. So let's look at what needs to be done, why and how. Keywords; English words are the words that are most frequently repeated in a typesetting page.
A search engine is a very complex and, importantly, very resource-intensive mechanism (this means not only material resources, but also human ones). Behind the seemingly simple , or its ascetic analogue from Google, there are thousands of employees, hundreds of thousands of servers and many billions of investments that are necessary for this colossus to continue to operate and remain competitive.
Page title; this is the phrase that appears in the top bar of your browser, as well as in the title of your “card” in search results. Description of the page; This is short text that appears below the page title in search results. This text also has a recommended character limit and is mainly intended to give the user what they will find when they click on their site.
Being very general at this time is a shot in the foot, because every click that a user discards from reading, i.e., that he considers inappropriate, will increase his rejection rate and therefore his position in the results every day.
Entering this market now and starting from scratch is more of a utopia than a real business project. For example, one of the world's richest corporations, Microsoft, has been trying to gain a foothold in the search market for decades, and only now their search engine Bing is slowly beginning to meet their expectations. And before that there was a whole series of failures and setbacks.
Title of content; This is the text that appears prominently on the page, the title of the layout. This is the first test of fire as to the significance of its contents. Keeping in mind that we are analyzing the conversion funnel, this will be the text that the user will read immediately after they are convinced that you have the answer that they need.
Pages with many titles dilute the words, taking away the relevance of the content that really needs to be highlighted. Content; this is the text that the user will have access to when visiting your page. It is worth noting that in addition to text, images can also be customized to reinforce the relevance of the subject we want to address.
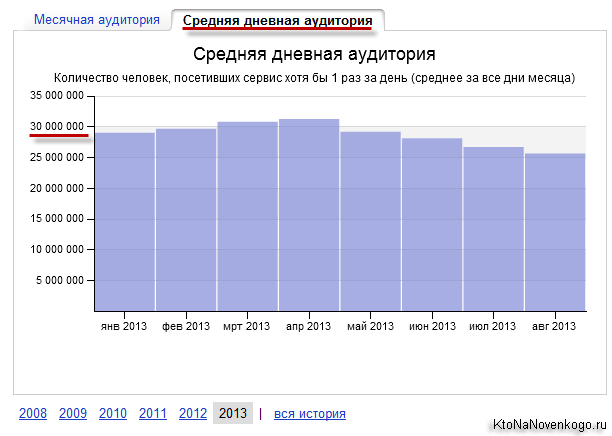
What can we say about entering this market without any special financial influences. For example, our domestic search engine Nigma has a lot of useful and innovative things in its arsenal, but their traffic is thousands of times lower than the leaders of the Russian market. For example, take a look at the daily Yandex audience:
The topics discussed above are basic and important methodology for a number of other search marketing strategies. In conclusion, it must be emphasized that the site is a living organism and requires attention and permanent job to stay relevant. In a globalized world where information reaches everyone at extreme speeds, content must be aligned with trends to provide users with innovation and information that truly adds up.
Of course, several times a day. But how can you improve this position and thereby achieve better results? This is where a group of techniques that, through the use of content and keywords, aim to position a website in the best possible way organically, that is, without buying media.
In this regard, we can assume that the list of the main (best and luckiest) search engines of the Runet and the entire Internet has already been formed and the whole intrigue lies only in who will eventually devour whom, or how their percentage share will be distributed if they all survive and will stay afloat.
Russian search engine market is very clearly visible and here, probably, we can distinguish two or three main players and a couple of minor ones. In general, a rather unique situation has developed in RuNet, which, as I understand it, has repeated itself only in two other countries in the world.
What results can you expect?
We know better than to find a client, he can be found. We focus on technology, so your brand is within reach of everything. The other 85% are repeat searches made by users. Are you interested in learning how it works?
What is artificial intelligence
The artificial intelligence we are talking about is not when the intelligence of a computer can be equated to the intelligence of a person.What is the difference between machine learning and artificial intelligence?
Artificial Intelligence is used to refer to computer systems who can learn and create new connections. It is primarily used to help search engines interpret searches for pages that do not contain exactly the same search terms.
I'm talking about the fact that the Google search engine, having come to Russia in 2004, has still not been able to take leadership. In fact, they tried to buy Yandex around this period, but something didn’t work out there and now “our Russia”, along with the Czech Republic and China, are those places where the almighty Google, if not defeated, then, in any case, met serious resistance.
But hasn't this happened before? Most of these queries are repeated, but 15% of new daily queries represent 450 million queries. A huge amount of new information is received every day. These new searches include complex multi-word searches.
He can see patterns between complex, seemingly unrelated studies and understand the similarities between them. Training allows the algorithm to better understand future complex searches and whether it is relevant to a certain topic. What is the name of the consumer at the highest level of the food chain?
In fact, to see the current state of affairs among the best search engines on the RuNet Anyone can. It will be enough to paste this URL into the address bar of your browser:
Http://www.liveinternet.ru/stat/ru/searches.html?period=month;total=yes
The fact is that most of them use .
"What is the name of the consumer at the highest level of the food chain." The term "consumer" can be a reference to customers or those who purchase something. But in scientific terms, it is what consumes food. There are also levels of consumers in the food chain. And who are the highest level consumers in the food chain?
Now let's see how similar the results are when we perform a more specific search, e.g. "Top level of the food chain." “How many tablespoons are in a cup?” How many tablespoons are in a glass? This is because each country's performance is different. So the answer is different for each country, although it is the same question.
After entering the given Url, you will see a picture that is not very attractive and presentable, but it well reflects the essence of the matter. Pay attention to the top five search engines from which sites in Russian receive traffic:

Yes, of course, not all resources with Russian-language content are located in this zone. There are also SU and RF, and general areas like COM or NET are full of Internet projects focused on Runet, but still, the sample is quite representative.
Even with the two examples above, it's not as revolutionary as you might imagine. Typically only throw big changes when they have a lot of confidence. But he didn't reveal more examples. It uses old survey data and learns to make predictions in the data. These factors can also be related to the user, such as where the user is located or the user's search history.
It sounds incredible, but it's true. It was a system designed for technological purposes, given its small user-friendly nature. It was the first major search engine to include external links in its algorithm as a criterion for site relevance. But, by the way, it is important to remember that she created the first system for personalizing web pages. Users could specify their preferences for your page, attach or accept news, weather, etc. it was also the first of the great free email portals.
This dependence can be presented in a more colorful way, as, for example, someone did online for his presentation:
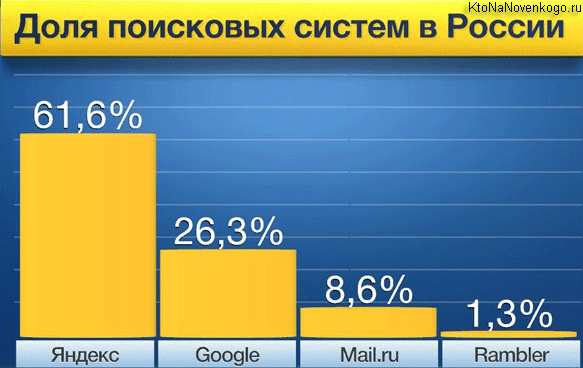
This doesn't change the essence. There are a couple of leaders and several very, very far behind search engines. By the way, I have already written about many of them. Sometimes it can be quite interesting to plunge into the history of success or, conversely, to delve into the reasons for the failures of once promising search engines.
So, in order of importance for Russia and the Runet as a whole, I will list them and give them brief characteristics:

The indexing process itself and the subsequent process of updating index databases are quite time-consuming. Although Google does this much faster than its competitors, at least Yandex, which takes a week or two to do this (read about).
Typically, a search engine breaks the text content of an Internet page into individual words, which are reduced to the basic principles, so that it can then give correct answers to questions asked in different morphological forms. All the extra stuff in the form of HTML tags, spaces, etc. things are deleted, and the remaining words are sorted alphabetically and their position in this document is indicated next to them.
This kind of thing is called a reverse index and allows you to search not by web pages, but by structured data located on the search engine servers.
The number of such servers for Yandex (which searches mainly only for Russian-language sites and a little for Ukrainian and Turkish) is in the tens or even hundreds of thousands, and for Google (which searches in hundreds of languages) - in the millions.
Many servers have copies, which serve both to increase the security of documents and help increase the speed of request processing (by distributing the load). Estimate the costs of maintaining this entire economy.
The user's request will be sent by the load balancer to the server segment that is currently least loaded. Then an analysis is carried out of the region from which the search engine user sent his request, and it is analyzed morphologically. If a similar query was recently entered in the search bar, then the user is given data from the cache so as not to overload the servers again.
If the request has not yet been cached, then it is transferred to the area where the search engine's index database is located. In response, you will receive a list of all Internet pages that are at least somewhat related to the request. Not only direct occurrences are taken into account, but also other morphological forms, as well as synonyms, homonyms, etc. things.
Their needs to be ranked and at this stage the algorithm (artificial intelligence) comes into play. In fact, the user's request is multiplied through all possible options for its interpretation, and answers to many requests are searched simultaneously (through the use of query language operators, some of which are available to ordinary users).
As a rule, the search results contain one page from each site (sometimes more). are now very complex and take into account many factors. In addition, to correct them, and are used, which manually evaluate reference sites, which allows you to adjust the operation of the algorithm as a whole.
In general, it is clear that the matter is dark. We can talk about this for a long time, but it is already clear that user satisfaction with a search system is achieved, oh, how difficult it is. And there will always be those who don’t like something, like you and me, dear readers.
Good luck to you! Before see you soon on the pages of the blog site How search engines work - snippets, algorithm reverse lookup, page indexing and features of Yandex
 How to check a website for broken links - Xenu Link Sleuth, plugin and online service Broken Link Checker, as well as search engines
How to check a website for broken links - Xenu Link Sleuth, plugin and online service Broken Link Checker, as well as search engines
 Electronic money in Russia and RuNet, as well as wallets in international payment systems Paypal - what is it, registration, replenishment of the account and how to use it, as well as how to withdraw money from Paypal in Russia Bing webmaster - center for webmasters from the Bing search engine
Electronic money in Russia and RuNet, as well as wallets in international payment systems Paypal - what is it, registration, replenishment of the account and how to use it, as well as how to withdraw money from Paypal in Russia Bing webmaster - center for webmasters from the Bing search engine